笔记:FNN做点击率预估中的实现思路
DNN这边一群大牛做了好几年了,已经有很深的技术积累。15年末到16年初当时做的multi GBDT +LR,想法上个人觉得已经很好,和业务的结合也反复在调试,最后还是在ctr+ecpm上被DNN甩开了很大距离。
我们这边有个专家工程师说过:目前点击率预估已是国内第一阵营,除非再出现如深度学习这种大的变革,剩下的就是精调网络结构了。所以你得认可一点: DNN网络结构之间的差异很大,有很大的精调空间。
本文就是DNN和FM的一种结合尝试,又称为FNN,由于业务的保密程度很高,所以本文只是记录FNN其中的一种结构,这并不是我们最终采用的结构。
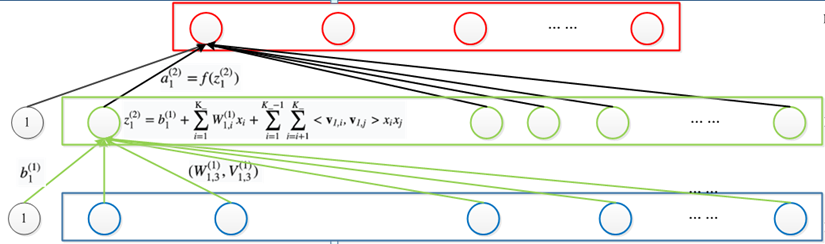
由于业务场景的限制,例如线上的预估时间,原始的DNN并不一定能将特征的cross发挥到最佳,所以可以在特征输入层后的embedding层将内积改为FM。增加特征之间的cross。
1. 神经网络基本原理
我们先定义神经网络如下图: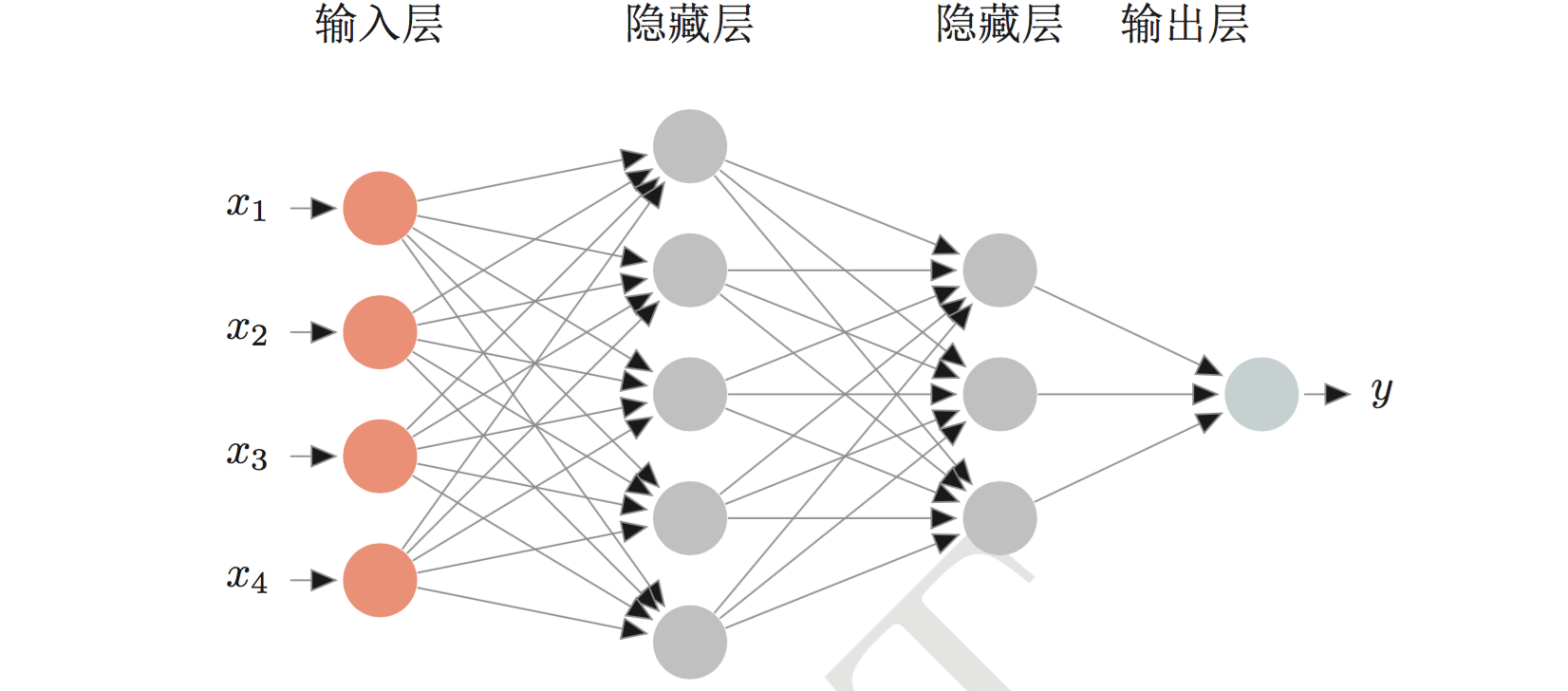
定义参数:
有:
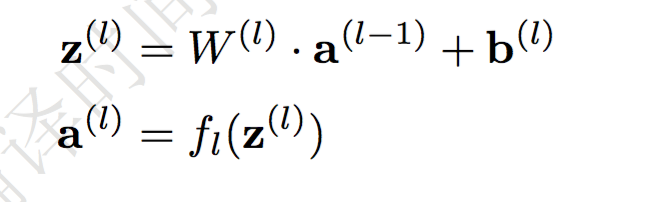
定义损失函数,一个误差函数加上一个正则化: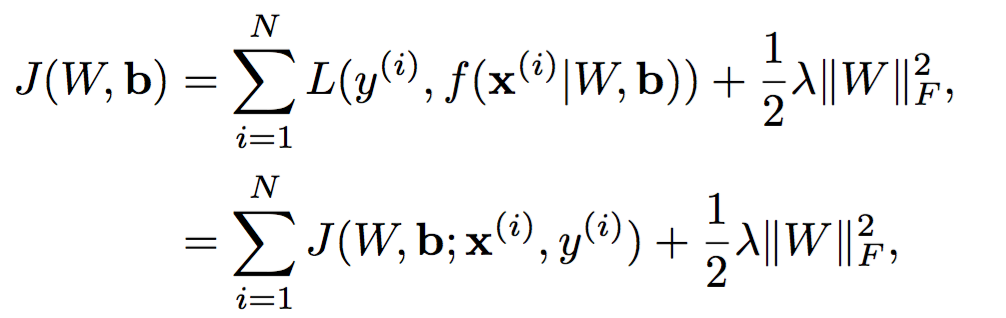
利用随机梯度下降来求解参数: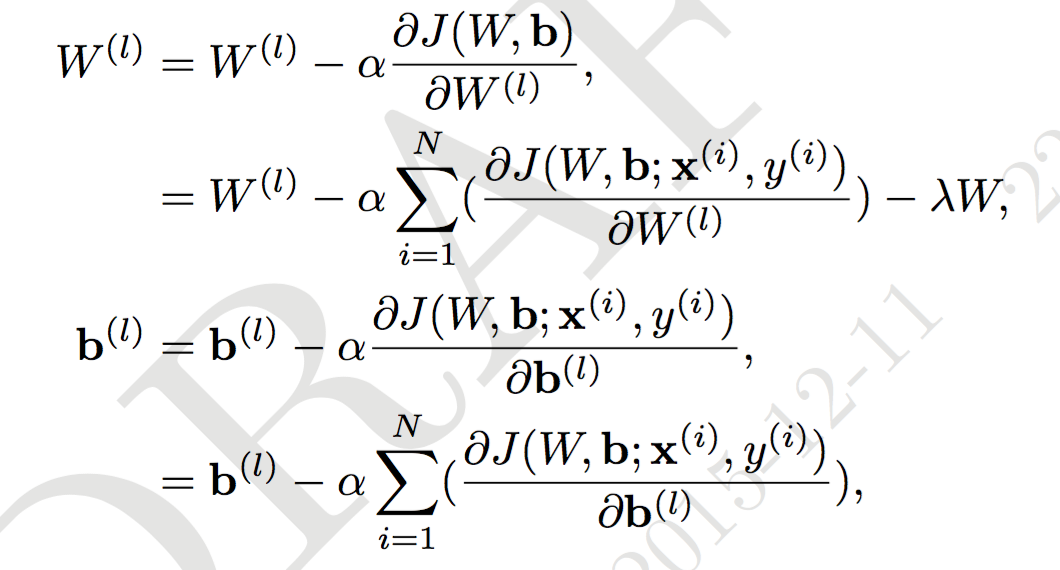
但是$\frac{\partial J(W,b)}{\partial W}$不好算,做下变形: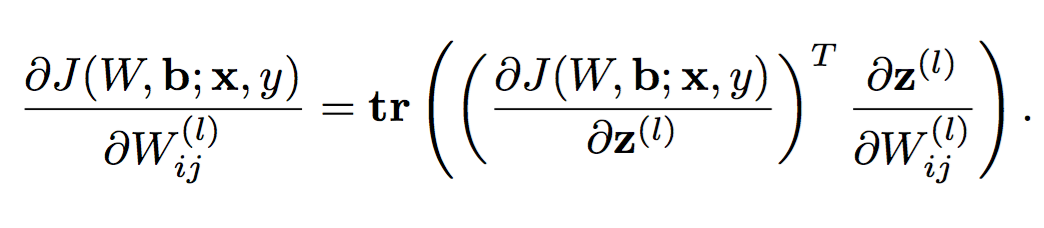
并定义误差项:
然后就能得到方向传播的公式:
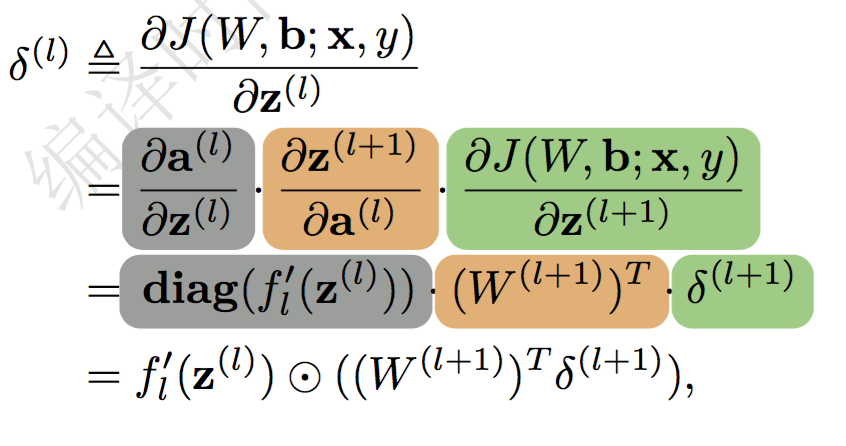
用一句话来表述这个公式:
$l$层的误差项等于与之相连的$l+1$层神经元上的误差项乘以连接的权值加和,然后再乘上激活函数的梯度。
这里可以顺便解释下,DNN里面的梯度消失问题。如果激活函数采用sigmoid,那这个激活函数的梯度会小于1,这样不断的往上一层传递的过程中误差项会越来越小,直至SGD无法对参数进行有效的优化。
于是,得到反向传播来估计参数的伪代码。(批量梯度下降版本)

2.FNN实现思路
FNN的变种有很多,这里说一个我们试验过的方法,并未达到最好的效果。由于业务保密程度很高,网络结构是核心技术,所以达到好效果的方法不能说。。。
把最后一层的神经元计算方式,从内积变成FM。FM的公式如下: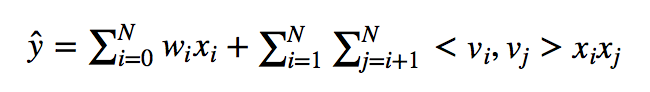
根据前面的公式,这里参数的优化,主要是计算$\frac{\partial z}{\partial w}$,即: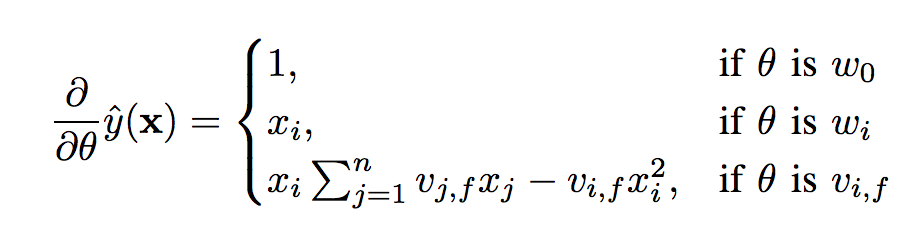
直接把这部分放到sgd优化参数的那部分就行了。这一层是不用加relu的,所以激活函数的梯度是直接设为1的。把这层的实现加到caffe里面,就能实现FNN了。